So Much More Acoustical Data, So Little Improvement in Results
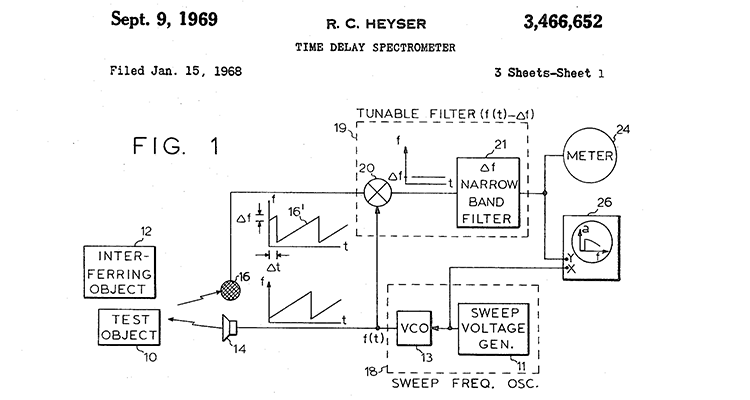 Half a century ago, the world of audio and acoustic measurement was changed forever with the invention of Time Delay Spectrometry and its evolution into what would later come the TEF Analyzer and other more sophisticated hardware. The original documents, patent and explanation can be found here.
Half a century ago, the world of audio and acoustic measurement was changed forever with the invention of Time Delay Spectrometry and its evolution into what would later come the TEF Analyzer and other more sophisticated hardware. The original documents, patent and explanation can be found here.
Dr. Heyser’s original sketch of the system is linked here [PDF].
We Need to Know — But Do We Know What We Need?
The need to know is ancient. In fact, for more than four centuries, natural philosophers and scientists have sought to quantify and derive qualitative standards for sound.
The problem we have now is: The precision and capability of today’s technology allows the pursuit of investigations into the finest detail and structure of sound and audio signals, on an unprecedented scale and that produces a
whole new paradigm.
Lost Among the Trees — Forgetting There is a Forest
We are capable of easily and quickly generating so much information that we are simply drowning in data. This causes even seasoned professionals to lose sight of the original question. Their situational awareness is being severely compromised by a virtual flood of information, so much so quickly that it is virtually impossible to adequately manage, interpret or prioritize the vital elements.
Perspective is being overwhelmed by the process, and the original intent is now only a vague memory, surrounded by a vast ocean of data, measurements and minute quantification of every conceivable parameter.
In a sense we are now facing a problem we have self-created. Let’s recall that only 25 years ago, the state of the measurement art revolved around the 1/3 octave Real Time Analyzer. Yes. Dr. Heyser was diligently developing his ideas based on his 1969 patent — a device the industry would come to know as the Crown (later Techron) TEF Analyzer, but the world was still living in 1/3 octave time.
It took a while to go from a rough, hand-drawn sketch on paper in 1969 to the reality of actual machines working from his ideas. In part, the slow acceptance of these new ideas was because at the time, the measurement world was solidly and comfortably using what they though were state of the measurement art devices – the numerous RTA iterations.
Practitioners were reluctant to invest in new systems given that they already had probably spent $1,000, or even considerably more, for the machines they had, which were often considered to be more accurate than was needed at that time. For reference, the Altec 8550 system was about $10,000 in 1970’s dollars (do the math).
But the biggest problem was perception. It was already assumed and taken as a fact that the RTA was capable of producing far more data that we could either use or need — so why develop something even more complex or even more precise? We already had more data than we could use.
The problem wasn’t new technology; it was physics. Essentially we could then — and certainly now — precisely quantify anomalies and other acoustic effects and impacts. The problem is not that we can’t measure it — the problem is that we can’t correct physical problems electronically, despite a lot of smoke and mirrors attempts to do so.
To a degree we can correct some problems with physical solutions such as absorption, damping, diffusion and so forth, but things like deep narrow band notches in a response curve are there until the universe ends. In classes I have always stated a simple conceptual practice for sound system tuning: Chop off response peaks; NEVER attempt to fill the valleys. Think of equalizers as cut-only devices when thinking about room acoustics and chances are you will stay out of trouble.
So Where Are We?
A quarter century later and the RTA is considered a low-tech toy found on your cell phone app store. With today’s products we’re getting resolutions three, four and five times as precise, for a quarter of the cost. You can use smart phones or tablets, but regardless of the hardware, the volume of data is so much larger that just post-processing a set of room responses could take days. With that thought in mind-the question should be:
What Is the Goal?
But the real question is can all the advanced technology allow us to do a better job of spectral balancing and response correction for speech intelligibility and coverage uniformity? Can we? Does the new, super precise, fractional octave data set give you any better results than we got a quarter century ago?
I would modestly suggest that the answer is… maybe. The problem so elegantly stated by Dr. Heyser some 40 years ago is still the issue. We know more, can measure with stunning precision, but that capability does not necessarily make for a better result for a listener. I have very serious reservations as to whether or not all the science we can throw at the problems is giving us any better answers.
Ultimately, it is the bio-acoustic judge sitting in the seats who will determine the level of success achieved. If they don’t hear the improvements, then all the technology in the known universe will not make the slightest difference. Ultimately, the legendary Don Davis said it best: “If bad sound were fatal, audio would be the leading cause of death on this planet.”
He still right 40+ years later!

More Stories Like This
Why Audio Isn’t an All-in-One-Size-Fits-All Proposition
Rewind 10 years ago, and the stack of hardware in a basic conference room included a display, an audiovisual matrix switcher, an audio amplifier, a control processor, a DSP, a hardware based codec, a PTZ camera, ceiling or table microphones, wall or ceiling speakers, and a proprietary touch panel. All that was held together with […]
AI and Pro Audio

By Stefan Marti Shure Artificial Intelligence (AI) is revolutionizing the audio industry. At least, that’s what we’ve heard lately — AI is creating new music, making it possible for your two favorite artists to release a collaboration, or even produce and release a brand-new song by The Beatles that had never been created before. What […]
An Interview With Matt Anderson, President and CEO of Sound Devices

This is an interview with Matt Anderson, president and CEO at Sound Devices, as written by Steph Beckett. It has been edited for clarity. Can you, first off, give me a little background on Sound Devices for those who might not be familiar? We’ve been around since 1998. I’m one of the original founders … […]